- 浏览: 21490556 次
- 性别:

- 来自: 杭州
-

最新评论
-
ZY199266:
配置文件还需要额外的配置ma
Android 客户端通过内置API(HttpClient) 访问 服务器(用Spring MVC 架构) 返回的json数据全过程 -
ZY199266:
我的一访问为什么是 /mavenwebdemo/WEB-I ...
Android 客户端通过内置API(HttpClient) 访问 服务器(用Spring MVC 架构) 返回的json数据全过程 -
lvgaga:
我又一个问题就是 如果像你的这种形式写。配置文件还需要额外的 ...
Android 客户端通过内置API(HttpClient) 访问 服务器(用Spring MVC 架构) 返回的json数据全过程 -
lvgaga:
我的一访问为什么是 /mavenwebdemo/WEB-I ...
Android 客户端通过内置API(HttpClient) 访问 服务器(用Spring MVC 架构) 返回的json数据全过程 -
y1210251848:
你的那个错误应该是项目所使用的目标框架不支持吧
log4net配置(web中使用log4net,把web.config放在单独的文件中)
Mysql 执行计划(Explain) 说明
Depending on thedetails of your tables, columns, indexes, and the conditions in your WHEREclause, the MySQL optimizer considers many techniques to efficiently performthe lookups involved in an SQL query. A query on a huge table can be performedwithout reading all the rows; a join involving several tables can be performedwithout comparing every combination of rows. The set of operations that theoptimizer chooses to perform the most efficient query is called the “queryexecution plan”, also known as the EXPLAIN plan.
--优化器根据表,列,索引以及查询条件,指定了一个查询路径,以实现高效的性能,这个查询的路径就称为’query execution plan’. 这个和Oracle的执行计划是一个感念。
Your goals areto recognize the aspects of the EXPLAIN plan that indicate a query is optimizedwell, and to learn the SQL syntax and indexing techniques to improve the planif you see some inefficient operations.
查看执行计划示例:
mysql> explain select * from user where User='root';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type |possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1| SIMPLE | user | ALL| NULL | NULL | NULL | NULL |7 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from user whereUser='root' \G
*************************** 1. row***************************
id: 1
select_type: SIMPLE
table: user
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 7
Extra: Using where
1 row in set (0.00 sec)
一.OptimizingQueries with EXPLAIN
The EXPLAINstatement can be used either as a way to obtain information about how MySQLexecutes a statement, or as a synonym for DESCRIBE:
(1)When youprecede a SELECT statement with the keyword EXPLAIN, MySQL displays informationfrom the optimizer about the query execution plan. That is, MySQL explains howit would process the statement, including information about how tables are joinedand in which order. EXPLAIN EXTENDED can be used to provide additionalinformation.
(2) EXPLAINPARTITIONS is useful only when examining queries involving partitioned tables.
(3) EXPLAINtbl_name is synonymous with DESCRIBE tbl_name or SHOW COLUMNS FROM tbl_name.
With the help ofEXPLAIN, you can see where you should add indexes to tables so that thestatement executes faster by using indexes to find rows. You can also useEXPLAIN to check whether the optimizer joins the tables in an optimal order. Togive a hint to the optimizer to use a join order corresponding to the order inwhich the tables are named in a SELECT statement, begin the statement with SELECTSTRAIGHT_JOIN rather than just SELECT.
If you have aproblem with indexes not being used when you believe that they should be, runANALYZE TABLE to update table statistics, such as cardinality of keys, that canaffect the choices the optimizer makes.
二.EXPLAINOutput Format
The EXPLAINstatement provides information about the execution plan for a SELECT statement.
EXPLAIN returnsa row of information for each table used in the SELECT statement. It lists thetables in the output in the order that MySQL would read them while processingthe statement. MySQL resolves all joins using a nested-loop join method. Thismeans that MySQL reads a row from the first table, and then finds a matchingrow in the second table, the third table, and so on. When all tables areprocessed, MySQL outputs the selected columns and backtracks through the tablelist until a table is found for which there are more matching rows. The nextrow is read from this table and the process continues with the next table.
When theEXTENDED keyword is used, EXPLAIN produces extra information that can be viewedby issuing a SHOW WARNINGS statement following the EXPLAIN statement. Thisinformation displays how the optimizer qualifies table and column names in theSELECT statement, what the SELECT looks like after the application of rewritingand optimization rules, and possibly other notes about the optimization process.EXPLAIN EXTENDED also displays the filtered column.
Note
You cannot usethe EXTENDED and PARTITIONS keywords together in the same EXPLAIN statement.
--Explain 不支持Extended 和partiions。
2.1 EXPLAIN Output Columns
This sectiondescribes the output columns produced by EXPLAIN. Later sections provideadditional information about the type and Extra columns.
Each output rowfrom EXPLAIN provides information about one table. Each row contains the valuessummarized in Table 7.1, “EXPLAIN Output Columns”, and described in more detailfollowing the table.
--MySQL 执行计划的输出选项如下表所示:
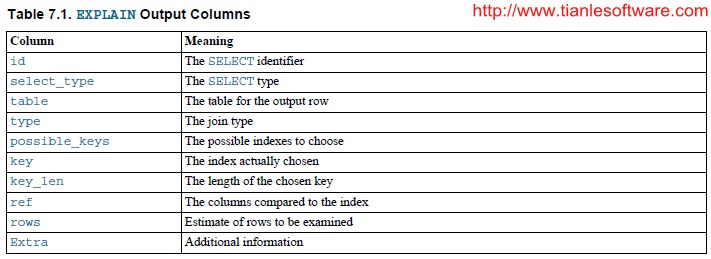
下面具体看看每项的含义:
2.1.1 id
The SELECTidentifier. This is the sequential number of the SELECT within the query.
--Query Optimizer 所选定的执行计划中查询的序列号;
2.1.2 select_type
The type of SELECT,which can be any of those shown in the following table.
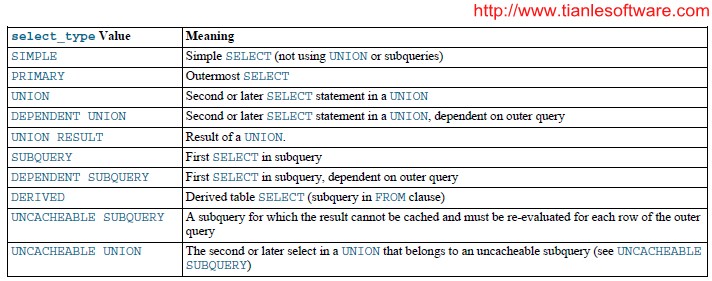
DEPENDENTtypically signifies the use of a correlated subquery. See Section 12.2.10.7,“Correlated Subqueries”.
DEPENDENTSUBQUERY evaluation differs from UNCACHEABLE SUBQUERY evaluation. For DEPENDENTSUBQUERY, the subquery is re-evaluated only once for each set of differentvalues of the variables from its outer context. For UNCACHEABLE SUBQUERY, thesubquery is re-evaluated for each row of the outer context. Cacheability ofsubqueries is subject to the restrictions detailed in Section 7.9.3.1, “How theQuery Cache Operates”.
所使用的查询类型,主要有以下这几种查询类型
(1)SIMPLE:除子查询或者UNION 之外的其他查询;
(2)PRIMARY:子查询中的最外层查询,注意并不是主键查询;
(3)UNION:UNION 语句中第二个SELECT 开始的后面所有SELECT,第一个SELECT 为PRIMARY
(4)UNION RESULT:UNION 中的合并结果;
(5)SUBQUERY:子查询内层查询的第一个SELECT,结果不依赖于外部查询结果集;
(6)DEPENDENT SUBQUERY:子查询中内层的第一个SELECT,依赖于外部查询的结果集;
(7)DEPENDENT UNION:子查询中的UNION,且为UNION 中从第二个SELECT 开始的后面所有SELECT,同样依赖于外部查询的结果集;
(8)UNCACHEABLE SUBQUERY:结果集无法缓存的子查询;
2.1.3 table
The table towhich the row of output refers.
--显示这一步所访问的数据库中的表的名称
2.1.4 type
The join type.For descriptions of the different types, see EXPLAIN Join Types.
--对表所使用的访问方式。
2.1.5 possible_keys
Thepossible_keys column indicates which indexes MySQL can choose from use to findthe rows in this table. Note that this column is totally independent of theorder of the tables as displayed in the output from EXPLAIN. That means thatsome of the keys in possible_keys might not be usable in practice with thegenerated table order.
If this columnis NULL, there are no relevant indexes. In this case, you may be able toimprove the performance of your query by examining the WHERE clause to checkwhether it refers to some column or columns that would be suitable forindexing. If so, create an appropriate index and check the query with EXPLAINagain. See Section 12.1.7, “ALTER TABLE Syntax”.
To see whatindexes a table has, use SHOW INDEX FROM tbl_name.
--该查询可以利用的索引. 如果没有任何索引可以使用,就会显示成null,这一项内容对于优化时候索引的调整非常重要;
2.1.6 key
The key columnindicates the key (index) that MySQL actually decided to use. If MySQL decidesto use one of the possible_keys indexes to look up rows, that index is listedas the key value.
It is possiblethat key will name an index that is not present in the possible_keys value.This can happen if none of the possible_keys indexes are suitable for lookingup rows, but all the columns selected by the query are columns of some otherindex.
That is, thenamed index covers the selected columns, so although it is not used to determinewhich rows to retrieve, an index scan is more efficient than a data row scan.
For InnoDB, a secondary index might coverthe selected columns even if the query also selects the primary key becauseInnoDB stores the primary key value with each secondary index. If key is NULL,MySQL found no index to use for executing the query more efficiently.
To force MySQLto use or ignore an index listed in the possible_keys column, use FORCE INDEX,USE INDEX, or IGNORE INDEX in your query. See Section 12.2.9.3, “Index HintSyntax”.
For MyISAMtables, running ANALYZE TABLE helps the optimizer choose better indexes. ForMyISAM tables, myisamchk --analyze does the same. See Section
12.7.2.1,“ANALYZE TABLE Syntax”, and Section 6.6, “MyISAM Table Maintenance and CrashRecovery”.
--MySQL Query Optimizer 从possible_keys 中所选择使用的索引;强制使用索引可以使用force index,use index 或者忽略索引ignore index。 对于MyISAM表,使用analyze table,可以帮助优化器选择更加的索引。
2.1.7 key_len
The key_lencolumn indicates the length of the key that MySQL decided to use. The length isNULL if the key column says NULL. Note that the value of key_len enables you todetermine how many parts of a multiple-part key MySQL actually uses.
--被选中使用索引的索引键长度;
2.1.8 ref
The ref columnshows which columns or constants are compared to the index named in the keycolumn to select rows from the table.
--列出是通过常量(const),还是某个表的某个字段(如果是join)来过滤(通过key)的;
2.1.9 rows
The rows columnindicates the number of rows MySQL believes it must examine to execute thequery.
For InnoDBtables, this number is an estimate, and may not always be exact.
--MySQL Query Optimizer 通过系统收集到的统计信息估算出来的结果集记录条数;
2.1.10 filtered
The filteredcolumn indicates an estimated percentage of table rows that will be filtered bythe table condition. That is, rows shows the estimatednumber of rows examined and rows × filtered / 100 shows the number of rows thatwill be joined with previous tables. This column is displayed if you useEXPLAIN EXTENDED.
2.1.11 Extra
This columncontains additional information about how MySQL resolves the query. Fordescriptions of the different values, see EXPLAIN Extra Information.
--查询中每一步实现的额外细节信息
2.2 EXPLAIN Join Types
The type columnof EXPLAIN output describes how tables are joined. The following list describesthe join types, ordered from the best type to the worst:
--对表所使用的访问方式。
2.2.1 system
The table hasonly one row (= system table). This is a special case of the const join type.
--系统表,表中只有一行数据;
2.2.2 const
The table has atmost one matching row, which is read at the start of the query. Because thereis only one row, values from the column in this row can be regarded asconstants by the rest of the optimizer. const tables are very fast because theyare read only once.
--读常量,且最多只会有一条记录匹配,由于是常量,所以实际上只需要读一次;
const is usedwhen you compare all parts of a PRIMARY KEY or UNIQUE index to constant values.In the following queries, tbl_name can be used as a const table:
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name
WHERE primary_key_part1=1 ANDprimary_key_part2=2;
2.2.3 eq_ref
One row is readfrom this table for each combination of rows from the previous tables. Otherthan the system and const types, this is the best possible join type. It isused when all parts of an index are used by the join and the index is a PRIMARYKEY or UNIQUE NOT NULL index.
--eq_ref:最多只会有一条匹配结果,一般是通过主键或者唯一键索引来访问;
eq_ref can beused for indexed columns that are compared using the = operator. The comparisonvalue can be a constant or an expression that uses columns from tables that areread before this table. In the following examples, MySQL can use an eq_ref jointo process ref_table:
SELECT * FROM ref_table,other_table
WHEREref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
2.2.4 ref
All rows withmatching index values are read from this table for each combination of rowsfrom the previous tables. ref is used if the join uses only a leftmost prefixof the key or if the key is not a PRIMARY KEY or UNIQUE index (in other words,if the join cannot select a single row based on the key value). If the key thatis used matches only a few rows, this is a good join type.
--ref:Join 语句中被驱动表索引引用查询;
ref can be usedfor indexed columns that are compared using the = or <=> operator. In thefollowing examples, MySQL can use a ref join to process ref_table:
SELECT * FROM ref_table WHEREkey_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHEREref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
2.2.5 fulltext
The join isperformed using a FULLTEXT index.
2.2.6 ref_or_null
This join typeis like ref, but with the addition that MySQL does an extra search for rowsthat contain NULL values. This join type optimization is used most often inresolving subqueries. In the following examples, MySQL can use a ref_or_nulljoin to process ref_table:
SELECT * FROM ref_table
WHERE key_column=expr OR key_column ISNULL;
--与ref 的唯一区别就是在使用索引引用查询之外再增加一个空值的查询;
2.2.7 index_merge
This join typeindicates that the Index Merge optimization is used. In this case, the keycolumn in the output row contains a list of indexes used, and key_len containsa list of the longest key parts for the indexes used. For more information, seeSection 7.13.2, “Index Merge Optimization”.
--查询中同时使用两个(或更多)索引,然后对索引结果进行merge 之后再读取表数据;
2.2.8 unique_subquery
This typereplaces ref for some IN subqueries of the following form:
value IN (SELECT primary_key FROMsingle_table WHERE some_expr)
unique_subqueryis just an index lookup function that replaces the subquery completely forbetter efficiency.
--子查询中的返回结果字段组合是主键或者唯一约束;
2.2.9 index_subquery
This join typeis similar to unique_subquery. It replaces IN subqueries, but it works fornonunique indexes in subqueries of the following form:
value IN (SELECTkey_column FROM single_table WHERE some_expr)
--子查询中的返回结果字段组合是一个索引(或索引组合),但不是一个主键或者唯一索引;
2.2.10 range
Only rows thatare in a given range are retrieved, using an index to select the rows. The keycolumn in the output row indicates which index is used. The key_len containsthe longest key part that was used. The ref column is NULL for this type.
--索引范围扫描;
range can beused when a key column is compared to a constant using any of the =, <>,>, >=, <, <=, IS NULL, <=>, BETWEEN, or IN() operators:
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1 = 10 AND key_part2 IN(10,20,30);
2.2.11 index
This join typeis the same as ALL, except that only the index tree is scanned. This usually isfaster than ALL because the index file usually is smaller than the data file.
MySQL can use this join type when the queryuses only columns that are part of a single index.
--全索引扫描;
2.2.12 ALL
A full tablescan is done for each combination of rows from the previous tables. This isnormally not good if the table is the first table not marked const, and usuallyvery bad in all other cases. Normally, you can avoid ALL by adding indexes thatenable row retrieval from the table based on constant values or column valuesfrom earlier tables.
--全表扫描
2.3 EXPLAIN Extra Information
The Extra columnof EXPLAIN output contains additional information about how MySQL resolves thequery. The following list explains the values that can appear in this column.If you want to make your queries as fast as possible, look out for Extra valuesof Using filesort and Using temporary.
2.3.1 Child of 'table' pushed join@1
This table isreferenced as the child of table in a join that can be pushed down to the NDBkernel. Applies only in MySQL Cluster NDB 7.2 and later, when pushed-down joinsare enabled. See the description of the ndb_join_pushdown server systemvariable for more information and examples.
2.3.2 const row not found
For a query suchas SELECT ... FROM tbl_name, the table was empty.
2.3.3 Distinct
MySQL is lookingfor distinct values, so it stops searching for more rows for the current rowcombination after it has found the first matching row.
2.3.4 Full scan on NULL key
This occurs forsubquery optimization as a fallback strategy when the optimizer cannot use anindex-lookup access method.
2.3.5 Impossible HAVING
The HAVINGclause is always false and cannot select any rows.
2.3.6 Impossible WHERE
The WHERE clauseis always false and cannot select any rows.
2.3.7 Impossible WHERE noticed afterreading const tables
MySQL has readall const (and system) tables and notice that the WHERE clause is always false.
2.3.8 No matching min/max row
No row satisfiesthe condition for a query such as SELECT MIN(...) FROM ... WHERE condition.
2.3.9 no matching row in const table
For a query witha join, there was an empty table or a table with no rows satisfying a uniqueindex condition.
2.3.10 No tables used
The query has noFROM clause, or has a FROM DUAL clause.
2.3.11 Not exists
MySQL was ableto do a LEFT JOIN optimization on the query and does not examine more rows inthis table for the previous row combination after it finds one row that matchesthe LEFT JOIN criteria. Here is an example of the type of query that can beoptimized this way:
SELECT * FROM t1 LEFT JOIN t2 ONt1.id=t2.idWHERE t2.id IS NULL;
Assume thatt2.id is defined as NOT NULL. In this case, MySQL scans t1 and looks up therows in t2 using the values of t1.id. If MySQL finds a matching row in t2, itknows that t2.id can never be NULL, and does not scan through the rest of the rowsin t2 that have the same id value. In other words, for each row in t1, MySQLneeds to do only a single lookup in t2, regardless of how many rows actuallymatch in t2.
2.3.12 Range checked for each record (indexmap: N)
MySQL found nogood index to use, but found that some of indexes might be used after columnvalues from preceding tables are known. For each row combination in thepreceding tables, MySQL checks whether it is possible to use a range orindex_merge access method to retrieve rows. This is not very fast, but isfaster than performing a join with no index at all. The applicability criteria areas described in Section 7.13.1, “Range Optimization”, and Section 7.13.2,“Index Merge Optimization”, with the exception that all column values for thepreceding table are known and considered to be constants.
Indexes arenumbered beginning with 1, in the same order as shown by SHOW INDEX for thetable. The index map value N is a bitmask value that indicates which indexesare candidates. For example, a value of 0x19 (binary 11001) means that indexes1, 4, and 5 will be considered.
2.3.13 Scanned N databases
This indicateshow many directory scans the server performs when processing a query forINFORMATION_SCHEMA tables, as described in Section 7.2.4, “OptimizingINFORMATION_SCHEMA Queries”. The value of N can be 0, 1, or all.
2.3.14 Select tables optimized away
The querycontained only aggregate functions (MIN(), MAX()) that were all resolved usingan index, or COUNT(*) for MyISAM, and no GROUP BY clause. The optimizerdetermined that only one row should be returned.
2.3.15 Skip_open_table, Open_frm_only,Open_trigger_only, Open_full_table
These valuesindicate file-opening optimizations that apply to queries forINFORMATION_SCHEMA tables, as described in Section 7.2.4, “OptimizingINFORMATION_SCHEMA Queries”.
2.3.16 Skip_open_table: Table files do notneed to be opened. The information has already become available within thequery by scanning the database directory.
2.3.17 Open_frm_only: Only the table's .frmfile need be opened.
2.3.18 Open_trigger_only: Only the table's.TRG file need be opened.
2.3.19 Open_full_table: The unoptimizedinformation lookup. The .frm, .MYD, and .MYI files must be opened.
2.3.20 unique row not found
For a query suchas SELECT ... FROM tbl_name, no rows satisfy the condition for a UNIQUE indexor PRIMARY KEY on the table.
2.3.21 Using filesort
MySQL must do anextra pass to find out how to retrieve the rows in sorted order. The sort isdone by going through all rows according to the join type and storing the sortkey and pointer to the row for all rows that match the WHERE clause. The keysthen are sorted and the rows are retrieved in sorted order. See Section 7.13.9,“ORDER BY Optimization”.
--当我们的Query 中包含ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。
2.3.22 Using index
The columninformation is retrieved from the table using only information in the indextree without having to do an additional seek to read the actual row. Thisstrategy can be used when the query uses only columns that are part of a singleindex.
If the Extra column also says Using where,it means the index is being used to perform lookups of key values. WithoutUsing where, the optimizer may be reading the index to avoid reading data rowsbut not using it for lookups. For example, if the index is a covering index forthe query, the optimizer may scan it without using it for lookups.
For InnoDBtables that have a user-defined clustered index, that index can be used evenwhen Using index is absent from the Extra column. This is the case if type is indexand key is PRIMARY.
--所需要的数据只需要在Index 即可全部获得而不需要再到表中取数据;
2.3.23 Using index forgroup-by
Similar to theUsing index table access method, Using index for group-by indicates that MySQLfound an index that can be used to retrieve all columns of a GROUP BY orDISTINCT query without any extra disk access to the actual table. Additionally,the index is used in the most efficient way so that for each group, only a fewindex entries are read. For details, see Section 7.13.10, “GROUP BYOptimization”.
--数据访问和Using index 一样,所需数据只需要读取索引即可,而当Query 中使用了GROUPBY 或者DISTINCT 子句的时候,如果分组字段也在索引中,Extra 中的信息就会是Using index forgroup-by;
2.3.24 Using join buffer
Tables from earlier joins are read inportions into the join buffer, and then their rows are used from the buffer toperform the join with the current table.
2.3.25 Using sort_union(...), Usingunion(...), Using intersect(...)
These indicate how index scans are mergedfor the index_merge join type. See Section 7.13.2, “Index Merge Optimization”.
2.3.26 Using temporary
To resolve thequery, MySQL needs to create a temporary table to hold the result. Thistypically happens if the query contains GROUP BY and ORDER BY clauses that listcolumns differently.
--当MySQL 在某些操作中必须使用临时表的时候,在Extra 信息中就会出现Using temporary 。主要常见于GROUP BY 和ORDER BY 等操作中。
2.3.27 Using where
A WHERE clauseis used to restrict which rows to match against the next table or send to theclient. Unless you specifically intend to fetch or examine all rows from thetable, you may have something wrong in your query if the Extra value is notUsing where and the table join type is ALL or index. Even if you are using anindex for all parts of a WHERE clause, you may see Using where if the columncan be NULL.
--如果我们不是读取表的所有数据,或者不是仅仅通过索引就可以获取所有需要的数据,则会出现Using where 信息;
2.3.28 Using where with pushed condition
This itemapplies to NDBCLUSTER tables only. It means that MySQL Cluster is using theCondition Pushdown optimization to improve the efficiency of a directcomparison between a nonindexed column and a constant. In such cases, thecondition is “pushed down” to the cluster's data nodes and is evaluated on alldata nodes simultaneously. This eliminates the need to send nonmatching rowsover the network, and can speed up such queries by a factor of 5 to 10 timesover cases where Condition Pushdown could be but is not used. For moreinformation, see Section 7.13.3, “Engine Condition Pushdown Optimization”.
--这是一个仅仅在NDBCluster 存储引擎中才会出现的信息,而且还需要通过打开ConditionPushdown 优化功能才可能会被使用。控制参数为engine_condition_pushdown 。
三.EstimatingQuery Performance
In most cases,you can estimate query performance by counting disk seeks. For small tables,you can usually find a row in one disk seek (because the index is probablycached). For bigger tables, you can estimate that, using B-tree indexes, youneed this many seeks to find a row: log(row_count) / log(index_block_length / 3* 2 / (index_length +data_pointer_length)) + 1.
--可以根据disk seeks的次数来估算query 性能。 对于小表,可能一次seek就可以搞定。 计算seeks的公式如下:
log(row_count) / log(index_block_length / 3 * 2 /(index_length +data_pointer_length)) + 1.
In MySQL, anindex block is usually 1,024 bytes and the data pointer is usually four bytes.For a 500,000-row table with a key value length of three bytes (the size ofMEDIUMINT), the formula indicates log(500,000)/log(1024/3*2/(3+4)) + 1 = 4 seeks.
--一个索引块通常是1024 bytes,data pointer 通常是4bytes。 如果一个表有500000行记录,每行3bytes,那么seeks的操作就是4次。
This index wouldrequire storage of about 500,000 * 7 * 3/2 = 5.2MB (assuming a typical indexbuffer fill ratio of 2/3), so you probably have much of the index in memory andso need only one or two calls to read data to find the row.
For writes,however, you need four seek requests to find where to place a new index valueand normally two seeks to update the index and write the row.
Note that thepreceding discussion does not mean that your application performance slowlydegenerates by log N. As long as everything is cached by the OS or the MySQLserver, things become only marginally slower as the table gets bigger. Afterthe data gets too big to be cached, things start to go much slower until yourapplications are bound only by disk seeks (which increase by log N). To avoidthis, increase the key cache size as the data grows. For MyISAM tables, the keycache size is controlled by the key_buffer_size system variable. See Section7.11.2, “Tuning Server Parameters”.
四.Controllingthe Query Optimizer
MySQL providesoptimizer control through system variables that affect how query plans areevaluated and which switchable optimizations are enabled.
4.1 Controlling Query Plan Evaluation
The task of thequery optimizer is to find an optimal plan for executing an SQL query. Becausethe difference in performance between “good” and “bad” plans can be orders ofmagnitude (that is, seconds versus hours or even days), most query optimizers,including that of MySQL, perform a more or less exhaustive search for anoptimal plan among all possible query evaluation plans. For join queries, thenumber of possible plans investigated by the MySQL optimizer growsexponentially with the number of tables referenced in a query. For smallnumbers of tables (typically less than 7 to 10) this is not a problem. However,when larger queries are submitted, the time spent in query optimization mayeasily become the major bottleneck in the server's performance.
A more flexiblemethod for query optimization enables the user to control how exhaustive theoptimizer is in its search for an optimal query evaluation plan. The generalidea is that the fewer plans that are investigated by the optimizer, the lesstime it spends in compiling a query. On the other hand, because the optimizerskips some plans, it may miss finding an optimal plan.
The behavior of the optimizer with respect to the number ofplans it evaluates can be controlled using two system variables:
--optimizer 使用2个系统变量来估算执行计划
(1) Theoptimizer_prune_level variable tells the optimizer to skip certain plans basedon estimates of the number of rows accessed for each table. Our experienceshows that this kind of “educated guess” rarely misses optimal plans, and maydramatically reduce query compilation times. That is why this option is on(optimizer_prune_level=1) by default. However, if you believe that theoptimizer missed a better query plan, this option can be switched off(optimizer_prune_level=0) with the risk that query compilation may take muchlonger. Note that, even with the use of this heuristic, the optimizer stillexplores a roughly exponential number of plans.
(2)Theoptimizer_search_depth variable tells how far into the “future” of eachincomplete plan the optimizer should look to evaluate whether it should beexpanded further. Smaller values of optimizer_search_depth may result in ordersof magnitude smaller query compilation times.
For example,queries with 12, 13, or more tables may easily require hours and even days to compileif optimizer_search_depth is close to the number of tables in the query. At thesame time, if compiled with optimizer_search_depth equal to 3 or 4, theoptimizer may compile in less than a minute for the same query. If you areunsure of what a reasonable value is for optimizer_search_depth, this variablecan be set to 0 to tell the optimizer to determine the value automatically.
4.2 Controlling Switchable Optimizations
The optimizer_switch system variable enables control over optimizer behavior. Itsvalue is a set of flags, each of which has a value of on or off to indicatewhether the corresponding optimizer behavior is enabled or disabled. Thisvariable has global and session values and can be changed at runtime. Theglobal default can be set at server startup.
To see the current set of optimizer flags,select the variable value:
mysql> SELECT @@optimizer_switch\G
*************************** 1. row***************************
@@optimizer_switch: index_merge=on,index_merge_union=on,
index_merge_sort_union=on,
index_merge_intersection=on,
engine_condition_pushdown=on
To change thevalue of optimizer_switch, assign a value consisting of a comma-separated listof one or more commands:
SET [GLOBAL|SESSION] optimizer_switch='command[,command]...';
Each command value should have one of theforms shown in the following table.

The order of thecommands in the value does not matter, although the default command is executedfirst if present. Setting an opt_name flag to default sets it to whichever ofon or off is its default value. Specifying any given opt_name more than once inthe value is not permitted and causes an error. Any errors in the value causethe assignment to fail with an error, leaving the value of optimizer_switchunchanged.
The followingtable lists the permissible opt_name flag names, grouped by optimizationstrategy.

The flag forcondition pushdown was added in MySQL 5.5.3.
For informationabout Index Merge, see Section 7.13.2, “Index Merge Optimization”. Forinformation about engine condition pushdown, see Section 7.13.3, “EngineCondition Pushdown Optimization”.
When you assigna value to optimizer_switch, flags that are not mentioned keep their currentvalues. This makes it possible to enable or disable specific optimizerbehaviors in a single statement without affecting other behaviors. Thestatement does not depend on what other optimizer flags exist and what theirvalues are. Suppose that all Index Merge optimizations are enabled:
mysql> SELECT @@optimizer_switch\G
*************************** 1. row***************************
@@optimizer_switch:index_merge=on,index_merge_union=on,
index_merge_sort_union=on,
index_merge_intersection=on,
engine_condition_pushdown=on
If the server isusing the Index Merge Union or Index Merge Sort-Union access methods forcertain queries and you want to check whether the optimizer will perform betterwithout them, set the variable value like this:
mysql> SEToptimizer_switch='index_merge_union=off,index_merge_sort_union=off';
mysql> SELECT @@optimizer_switch\G
*************************** 1. row***************************
@@optimizer_switch:index_merge=on,index_merge_union=off,
index_merge_sort_union=off,
index_merge_intersection=on,
engine_condition_pushdown=on
-------------------------------------------------------------------------------------------------------
版权所有,文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
Blog: http://blog.csdn.net/tianlesoftware
Weibo: http://weibo.com/tianlesoftware
Email: tianlesoftware@gmail.com
Skype: tianlesoftware
-------加群需要在备注说明Oracle表空间和数据文件的关系,否则拒绝申请----
DBA1 群:62697716(满); DBA2 群:62697977(满)DBA3 群:62697850(满)
DBA 超级群:63306533(满); DBA4 群:83829929(满) DBA5群: 142216823(满)
DBA6 群:158654907(满) DBA8 群:172855474 DBA9群:102954821


发表评论

相关推荐
《MySQL 执行计划EXPLAIN说明.MD》该文档描述了有关MySQL 执行计划EXPLAIN各项参数说明,还文档基于Typora工具编写。内容是平时积累整理,仅供参考。文档中内容在博客...
在MySQL中,我们可以通过EXPLAIN命令获取MySQL如何执行SELECT语句的信息,包括在SELECT语句执行过程中表如何连接和连接的顺序。 下面分别对EXPLAIN命令结果的每一列进行说明: .select_type:表示SELECT的类型,常见...
目录 结果列说明: select_type:SELECT、SIMPLE(简单表,即不使用表连接和子查询)、PRIMARY(主查询,即外层的查询)、UNION(union...Extra:执行情况的说明和描述。 执行SQL: EXPLAIN select * from bs_demo
其中extended是选用的,如果使用的extended,那么explain之后就可以使用show warnings查看相应的优化信息,也就是mysql内部实际执行的query。 列名 描述 说明 相关链接 id 若没有子查询和联合查询,id则都...
explain显示了MySQL如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。简单讲,它的作用就是分析查询性能。 explain关键字的使用方法很简单,就是把它放在select查询语句的...
Mysql休闲说明 突出显示有问题MySQL解释结果。 受启发。 安装 将此行添加到您的应用程序的Gemfile中: gem 'mysql_casual_explain' 然后执行: $ bundle install 或将其自己安装为: $ gem install mysql_...
22-利用explain查看sql语句的执行计划.avi 23-DML之修改表中的记录实战.avi 24-小试牛刀初步增量恢复MySQL数据实战.avi 25-某企业运维全套面试题解答.avi 26-DML之修改表及企业严重故障案例解决实战.avi 27-删除表中...
如何通过EXPLAIN分析SQL语句的执行计划? 描述一下MySQL事务的ACID特性,并举例说明每种特性的实际应用场景。 解释不同事务隔离级别的含义以及可能导致的问题(脏读、不可重复读、幻读),并指出MySQL的默认隔离级别...
Mysql数据库优化实战,里面有一些小的例子来说明执行计划的讲解。
12.3.3 用EXPLAIN理解查询操作的工作过程 12.4 数据库的优化 12.4.1 设计优化 12.4.2 权限 12.4.3 表的优化 12.4.4 使用索引 12.4.5 使用默认值 12.4.6 其他技巧 12.5 备份MySQL数据库 12.6 恢复MySQL...
mysql 总结........................................................................................................................................6 1.1 数据库的种类.......................................
12.3.3 用EXPLAIN理解查询操作的工作过程 12.4 数据库的优化 12.4.1 设计优化 12.4.2 权限 12.4.3 表的优化 12.4.4 使用索引 12.4.5 使用默认值 12.4.6 其他技巧 12.5 备份MySQL数据库 12.6 恢复MySQL数据库 12.7 ...
12.3.3 用EXPLAIN理解查询操作的工作过程 12.4 数据库的优化 12.4.1 设计优化 12.4.2 权限 12.4.3 表的优化 12.4.4 使用索引 12.4.5 使用默认值 12.4.6 其他技巧 12.5 备份MySQL数据库 12.6 恢复MySQL...
目录 1、MySQL的基本架构 1)MySQL的基础架构图 2)查询数据库的引擎 3)指定数据库对象的存储引擎 2、SQL优化 1)为什么需要进行SQL优化?... 5、explain执行计划常用关键字详解
问题 通过「SHOW FULL PROCESSLIST」语句很容易就能查到问题SQL,如下: SELECT post.* FROM post INNER JOIN post_tag ON post.id = post_... 试着用EXPLAIN查询一下SQL执行计划(篇幅所限,结果有删减): +------
一、分析sql执行计划 1.通过explain查看 explain select * from stu; 2.执行计划关键字分析 字段 说明 id id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个...